| Woche | Datum | Thema | Ziele |
|---|---|---|---|
| 1 | 14. Apr. | Grundlagen & Kausalität | |
| 2 | 21. Apr. | Validität, Designs, Ethik | |
| 3 | 28. Apr. | Eine Problemstellung entwickeln* | |
| 4 | 5. Mai | Computational Methods* | |
| 5 | 12. Mai | Projekt-Sitzung | Präregistrierung |
| 6 | 19. Mai | Projekt-Sitzung | Pretest |
| 7 | 26. Mai | Keine Sitzung: Dienstreise |
Beginn Feldphase |
BA Experiment
Themenschwerpunkt: Algorithmisch kuratierte Unterhaltungsmedien
Felix Dietrich
Johannes Gutenberg-Universität Mainz
BA Experiment: Medienrezeption & -wirkung KF A
Sommersemester 2026
Willkommen!
- Sie können horizontal durch die Sitzungen und vertikal innerhalb der Sitzungen navigieren
- Verwenden Sie die Pfeiltasten
- Verwenden Sie “M”, um das Menü zu öffnen
- Die Kurs-Website und alle Folien finden Sie unter https://felixdidi.github.io/26-1-ex
- Drücken Sie
?auf Ihrer Tastatur, um mehr darüber zu erfahren, wie Sie durch die Folien navigieren können!
Sitzung 01: Einführung

Ressourcen für diese Sitzung
Eine kleine Einführung
Ich werde Ihnen eine kurze Geschichte erzählen.
Hierzu bitte eine Hälfte des Kurses kurz die Augen schließen!

Dieser Charakter heißt Grizzard.
Er spielt gleich in unserer Geschichte eine Rolle.

Dieser Charakter heißt Grizzard.
Er spielt gleich in unserer Geschichte eine Rolle.
“Grizzard würde anderen emotionales Leid zufügen.”
Bitte schreiben Sie sich eine Zahl zwischen…
1 (sehr unwahrscheinlich) und
7 (sehr wahrscheinlich) auf,
die Ihrem Eindruck entspricht.
Die Geschichte von Grizzard: Er hat die Entscheidung.
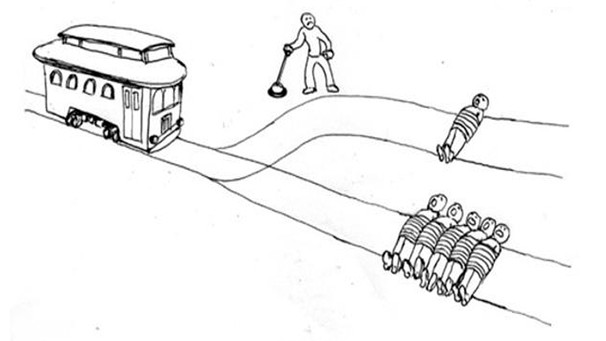
“Grizzard hat das richtige getan.”
Bitte schreiben Sie sich eine Zahl zwischen…
1 (stimme voll und ganz zu) und
7 (stimme überhaupt nicht zu) auf,
die Ihrem Eindruck entspricht.
Das haben Sie gesehen, bevor Sie die Fragen beantwortet haben:
Hero Grizzard
Villain Grizzard
Berechnen Sie jeweils einen Gruppenmittelwert für die erste und die zweite Frage. Wir tragen diese Werte gleich in die folgende Tabelle ein:
Agenda
- Einführung & Organisatorisches
- Grundlagen experimenteller Forschung
- Kausalität & Zusammenhänge
Los geht’s!
Welche sind die wichtigsten Fragen, die in dieser Sitzung beantwortet werden sollen?
- Worum geht es in diesem Kurs?
- Was werde ich lernen?
- Was werde ich tun (müssen)?
Kurs-Website
- Verfügbar unter https://felixdidi.github.io/26-1-ex
- Bitte nach dieser Sitzung im Detail ansehen
Kursmaterial
- Wird über die Kurs-Website (und Moodle) bereitgestellt
- Bitte prüfen Sie, ob Sie Zugang zur Moodle-Plattform haben
- Sie sollten automatisch zum Moodle-Kurs hinzugefügt werden
- Wenn Sie bis Ende dieser Woche keinen Zugang haben, schreiben Sie bitte eine E-Mail
Vorstellungsrunde

Über Felix
- Doktorand & wiss. Mitarbeiter
am Fachbereich Medienpsychologie
JGU Mainz
Meine Forschungsinteressen umfassen:
- Rezeption und Wirkung von Unterhaltungsmedien
- Algorithmische Kuratierung von Medieninhalten
- Digitale Autonomie & mentale Gesundheit
- Computational Communication Science
Und Sie?
- Wie ist Ihr Name?
- Was ist Ihr Haupt- und Nebenfach?
- Wie groß ist Ihr Interesse an computergestützten Analysemethoden?
Seminarübersicht
Hinweis
Die Seminarstruktur kann an die individuellen Bedürfnisse und Interessen der Projektgruppen angepasst werden. Sitzungen, die mit einem Sternchen markiert sind, qualifizieren anteilig für den Computional Methods Track.
Seminarübersicht
| Woche | Datum | Thema | Ziele |
|---|---|---|---|
| 8 | 2. Juni | Keine Sitzung: Dienstreise |
|
| 9 | 9. Juni | Keine Sitzung: Dienstreise |
|
| 10 | 16. Juni | Datenaufbereitung* | Ende Feldphase |
| 11 | 23. Juni | Datenanalyse | |
| 12 | 30. Juni | Datenanalyse | |
| 13 | 7. Juli | Semesterabschluss und Informationen zum Projektbericht | Projekt-Präsentation |
| 31. Aug. | Einreichungsfrist Projektbericht |
Hinweis
Die Seminarstruktur kann an die individuellen Bedürfnisse und Interessen der Projektgruppen angepasst werden. Sitzungen, die mit einem Sternchen markiert sind, qualifizieren anteilig für den Computional Methods Track.
Was werde ich lernen?
Was werde ich lernen?
Expertise
- Forschung zur digitalen Mediennutzung, Fokus auf algorithmische Kuratierung
- Umsetzung einer Experimentalstudie von der Konzeption bis zur Präsentation
Methodische Kompetenz
- Entwicklung empirischer, experimenteller Forschungsdesigns (Schwerpunkt Computational Communication Science)
- Durchführung und Dokumentation von Datenanalyse und Reflexion der methodischen Grenzen
Persönliche Kompetenz
- Problemlösungskompetenz bei forschungsorientierten Aufgaben
- Übertragung des Wissens auf ähnliche Fragestellungen
Was muss ich tun?
Was muss ich tun?
Keine Anwesenheitspflicht bedeutet…
- Sie erhalten alle grundlegenden Informationen im LMS und auf der Kurswebseite
- Sie können viele Kursinhalte selbständig vor- und nachbereiten
- Ein Teil der Aufgaben wird auf nicht-Präsenz-Zeiten verlagert
- Sie sind selbst verantwortlich, alle Inhalte aufzunehmen und alle zentralen Abgaben/Aufgaben/Voraussetzungen für die aktive Teilnahme zu erfüllen/im Blick zu behalten
- Wenn Sie nicht anwesend sind, es aber Gruppenarbeiten gibt, sind Sie selbst dafür verantwortlich, sich im Sinne der Gruppe einzubringen
- Gerade bei empirischen Kursen gibt es viele essenzielle Sitzungen, die direkt an den Erfolg in diesem Kurs geknüpft sind, d.h. kein Abschlussbericht ohne regelmäßige Anwesenheit oder sehr hohes Maß an eigenständiger Nachbereitung
Was muss ich tun?
Arbeit in den Arbeitsgruppen
- Gruppenarbeit im Seminar: ca. 4 Studierende pro Gruppe
- Maximal 5 Arbeitsgruppen im Seminar
- Prinzip: “Learning by doing”
- Studierende sammeln praktische Erfahrungen in Arbeitsgruppen (AGs)
- Austausch mit anderen AGs: Kennenlernen von Methoden, Themen und Arbeitsweisen
- Feedback geben und erhalten: zur eigenen und zu anderer AG-Arbeit
Was muss ich tun?
| Anforderung | Abgabe | Deadline |
|---|---|---|
| Aktive Teilnahme an Diskussionen und Gruppenarbeiten im Kurs | Fortlaufend | |
| Sitzungsvorbereitung durch Literatur-Lektüre & -Recherche | Fortlaufend | |
| Gruppen-Abgabe der (vorläufigen) Präregistrierung für das Forschungsprojekt | E-Mail an den Dozenten | Sonntag, 10.05., 23:59 Uhr |
| Pretest des Fragebogens & Rekrutierung von Studienteilnehmenden | Vor Beginn und während der Feldphase | |
| Abschlusspräsentation | E-Mail an den Dozenten | Abgabe Sonntag, 05.07., 23:59 Uhr; Präsentation Dienstag, 07.07., 16:15 Uhr |
Was muss ich tun?
Benotete Leistung (“Prüfungsleistung”)
- Schriftlicher Projektbericht (Gruppenabgabe)
- Orientiert sich an einem wissenschaftlichen Artikel
- Informationen auf der Kurswebsite & in der letzten Sitzung
Was muss ich tun?
Leseaufgabe (siehe “Vorbereitung” im Seminarplan)
- Lesen Sie die bereitgestellte Literatur, um sich auf eine Seminar-Sitzung vorzubereiten
- Orientieren Sie sich bei der Lektüre an den Fragen, die am Ende der letzten Sitzung gestellt wurden
- Sie sollten in der Lage sein, diese Fragen in der Sitzung zu beantworten
Wie man liest und wie man nicht lesen sollte?
- Lesen Sie wissenschaftliche Literatur nicht wie einen Roman
- Beginnen Sie mit Titel, Zusammenfassung und Zwischenüberschriften, um einen ersten Eindruck zu gewinnen
- Wenn Sie digital lesen, suchen Sie nach Schlüsselwörtern
- Überlegen Sie: “Was will ich von diesem Text?”
- Beantworten Sie Ihre eigenen Fragen (ich werde auch einige stellen)
Allgemeine Literatur

Soweit Fragen?
Grundlagen experimenteller Forschung
Angenommen, dass …
- … wir in den letzten 15 Jahren beobachtet hätten, dass Darstellungen von „Magermodels” in verschiedenen Werbemitteln (z.B. TV-Spots, Plakatwerbung, Social-Media-Werbung, …) zunehmen.
- … bevölkerungsrepräsentative Erhebungen (z.B. Statistisches Bundesamt) für denselben Zeitraum eine Zunahme von Essstörungen, v.a. Magersucht, verzeichnen.
- … Studien zeigen, dass junge Frauen, die häufig entsprechende Werbeinhalte rezipieren, vermehrt unter Essstörungen leiden.
Die Beobachtungen lassen einen Zusammenhang zwischen Werbeinhalten und Ernährungsverhalten vermuten – erlauben aber keine Kausalschlüsse.
Was also tun?
EXPERIMENT
Übung
Aufgabe (~10 Minuten)
Tauschen Sie sich mit Ihren Sitznachbar:innen aus:
- Was verbinden Sie mit dem Begriff „Experiment”?
- Was zeichnet ein gutes Experiment Ihrer Meinung nach aus?
- Was unterscheidet ein Experiment von anderen Arten (sozialwissenschaftlicher) Forschung?
Halten Sie die Ergebnisse stichpunktartig fest.
Was ist überhaupt ein Experiment?
- Überprüfung von Kausalannahmen: Untersuchung von Ursache-Wirkungs-Beziehungen
- Unabhängige vs. abhängige Variablen (UV/AV): Aktive Variation der UV; Messung der AV
- Unter kontrollierten Bedingungen: Äußere Umstände für alle Gruppen gleich; potenzielle Einflüsse ausgeschaltet, z.B. durch Randomisierung
- Untersuchungsanordnung: Das Experiment ist eine Art, empirisch zu forschen – keine Methode zur Datenerhebung!
„Ein Experiment ist eine Untersuchungsanordnung zur Überprüfung von Kausalannahmen, bei der unter kontrollierten Bedingungen mindestens eine unabhängige Variable aktiv variiert und deren Einfluss auf eine oder mehrere abhängige Variablen gemessen wird.” 1
Experimentallogik: Manipulation und Kontrolle
- Bildung von mindestens zwei Gruppen, die sich in allen Merkmalen gleichen
- Während des Ablaufs alle Faktoren und Rahmenbedingungen konstant halten
- Manipulation eines Stimulus → Experimentalgruppe(n) vs. Kontrollgruppe
- Messung der interessierenden AV → Unterschiede in der AV auf Manipulation zurückführbar
„Experimenten [liegt] eine bestechend einfache Logik zugrunde: […] Man kontrolliert alle sonstigen Bedingungen so präzise, dass die vorgenommene Manipulation der unabhängigen Variable als alleinige Ursache des etwaigen Effekts zurückbleibt.” 1
Das Experiment in der Forschungslandschaft
Experimentalforschung ist in verschiedenen Disziplinen ein gängiger Weg:
- Naturwissenschaften: Überprüfung von Naturgesetzen, Wirksamkeit chemischer Stoffe, tierisches Verhalten, …
- Sozialwissenschaften: Untersuchung von Verhalten, Emotionen und Kognitionen im gesellschaftlichen Kontext
- Kommunikationswissenschaft: Teildisziplin der Sozialwissenschaften; Untersuchung der Rolle von (medial vermittelter) Kommunikation
Experimentalforschung ist explanativ (→ Erklärung von Ursache-Wirkungs-Beziehungen) und wird zumeist an quantitative Methoden der Datenerhebung angebunden (z.B. Befragung, Beobachtung, physiologische Messungen).
Kausalität & Zusammenhänge

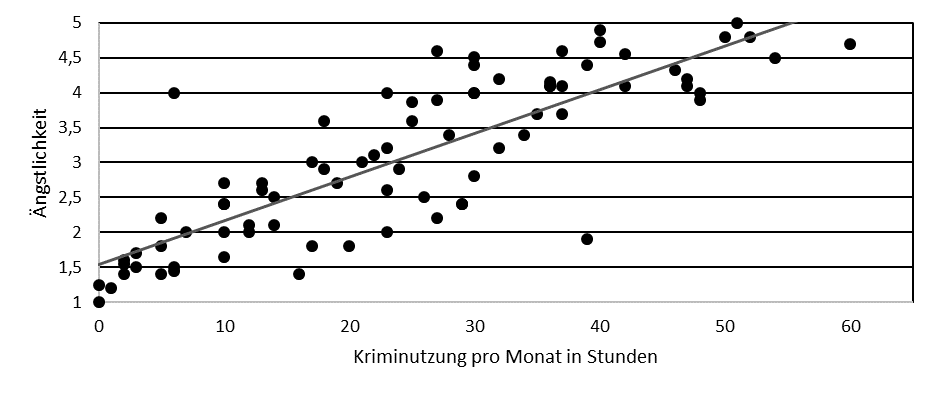
Stellen Sie sich vor, Sie führen eine repräsentative Befragung der deutschen Bevölkerung durch und messen:
- das Ausmaß der Ängstlichkeit (Skala 1–5)
- in welchem Umfang die Befragten Krimis sehen (Stunden pro Monat)
Sie können nun prüfen, ob die beiden Variablen zusammenhängen. Einen solchen Zusammenhang nennt man Korrelation.
Zusammenhänge und Korrelationen
Eine Korrelation ist eine Kovariation: Abweichungen vom Mittelwert der einen Variable gehen mit Abweichungen des Mittelwerts der anderen Variable einher.
Positiver Zusammenhang
je größer x, desto größer y
Negativer Zusammenhang
je größer x, desto kleiner y
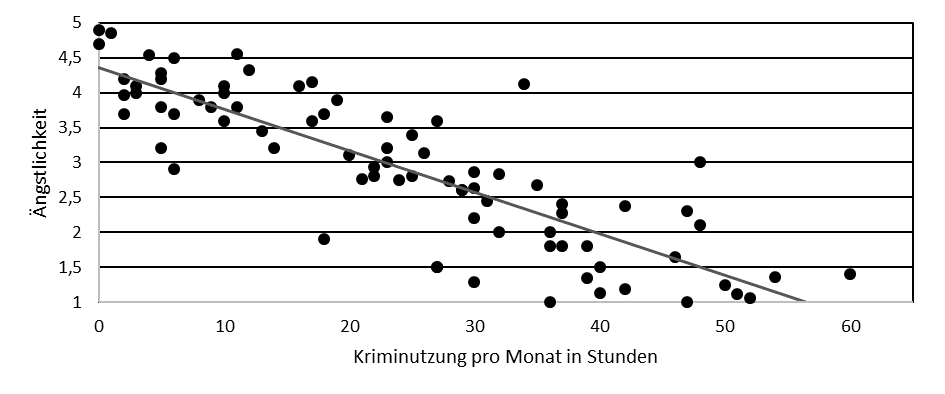
Die Stärke beschreibt ein standardisierter Korrelationskoeffizient von −1 bis +1.
Ursachen von Zusammenhängen
Sie finden eine positive Korrelation zwischen Ängstlichkeit und Kriminutzung.
Aufgabe (~10 Minuten)
- Wie könnte der Zusammenhang entstehen?
- Was sind potenzielle Ursachen für diese Beobachtung?
- Was könnte es bedeuten, dass es kausale und nicht-kausale Ursachen gibt?
Tauschen Sie sich mit Ihren Sitznachbar:innen aus.
Ursachen von Zusammenhängen
Kausaler Zusammenhang zwischen X und Y:
- X verursacht Y
- Y verursacht X
- X und Y bedingen sich gegenseitig
Nicht-kausaler Zusammenhang (Scheinkausalität):
- Eine Drittvariable Z verursacht den Zusammenhang
- Der Zusammenhang beruht auf einem Zufall
- Der Zusammenhang beruht auf methodischen Fehlern
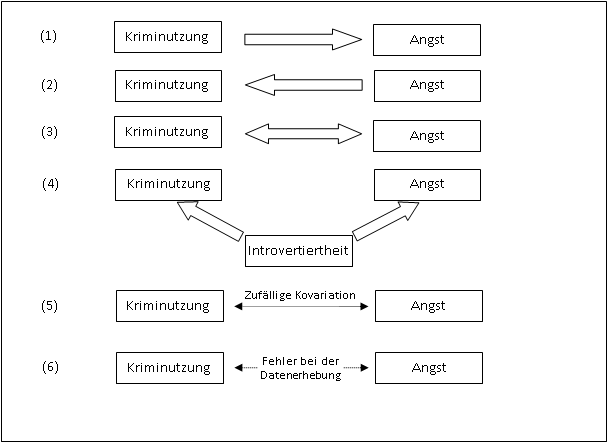
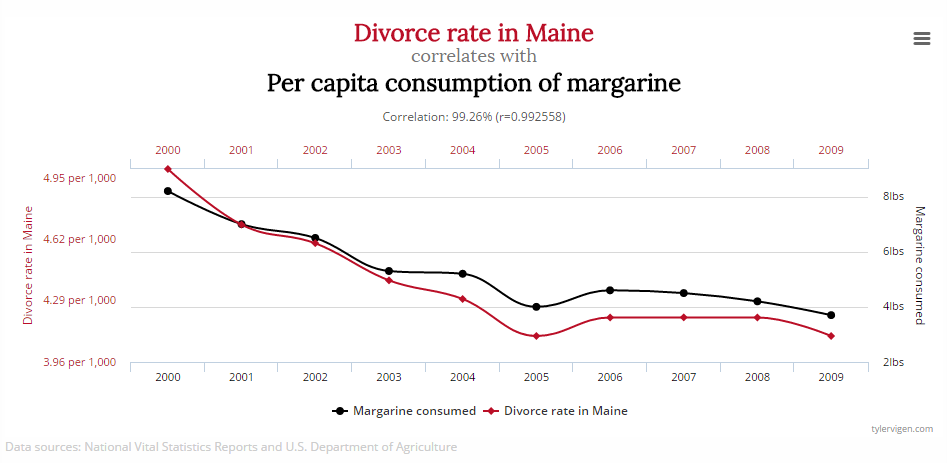
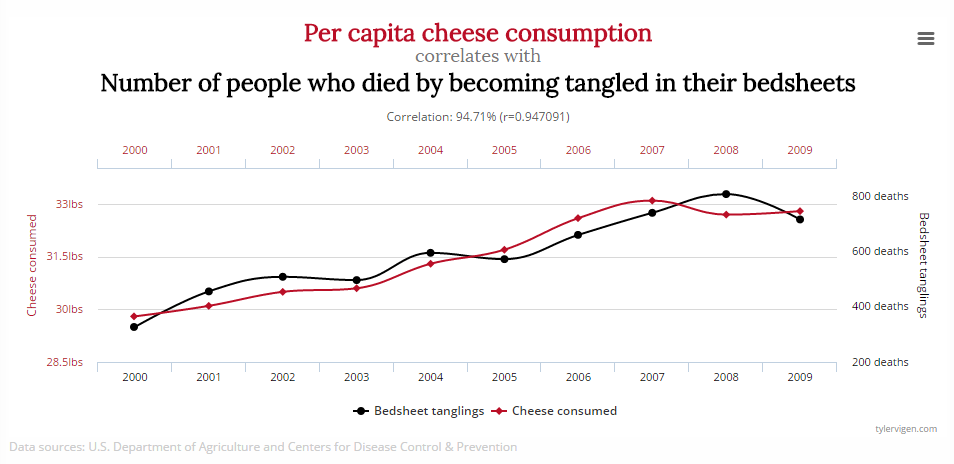
Scheinkausalität
- Robert Matthews1 findet einen starken Zusammenhang zwischen der Zahl der Störche und der Geburtenrate in 17 Ländern (r = .62). Bringen also Störche die Babys?
- Scheinkausalität (“Spurious Correlations”2) bezeichnet einen statistischen Zusammenhang, dem keine Ursache-Wirkungs-Logik zugrunde liegt.
- Gängiger Begriff “Scheinkorrelation” führt etwas in die Irre, da rechnerisch sehr wohl ein Zusammenhang besteht, diesem aber keine Kausalbeziehung zugrunde liegt.
- Menschliches Denken fehleranfällig für voreilige Kausalschlüsse (“post hoc, ergo propter hoc”: “danach, daher deswegen”).
Drei Bedingungen für den Nachweis von Kausalität
- Systematischer Zusammenhang zwischen der angenommenen Ursache und der angenommenen Wirkung
- Zeitliche Abfolge: Die Ursache muss vor der Wirkung auftreten
- Alternative Erklärungen ausschließen durch Konstanthalten aller anderen Variablen
Begriffsdefinition
Die Ursache nennen wir im Experiment unabhängige Variable, also jene Größe, von der man vermutet, dass sie einen entsprechenden Effekt ausübt. Von ihr unterscheidet man die abhängige Variable, die von der Ursache beeinflusst wird, also von ihr abhängt.
Gründe gegen den Einsatz experimenteller Forschung
Ethische Bedenken
Experimente sollten niemals durchgeführt werden, wenn Personen durch die Exposition des Stimulus psychischen oder physischen Schaden nehmen könnten.
- Beispiel I: Führt Pornografienutzung im frühen Jugendalter zu Misogynie?
- Beispiel II: Werther-Effekt
Methodische Hindernisse
Es gibt Fragestellungen, bei denen Experimente kaum umsetzbar sind.
- Beispiel I: Wie wirkt sich ein Umzug auf die Mediennutzungsgewohnheiten aus?
- Beispiel II: Führt eine intensive Nutzung von sozialen Netzwerken dazu, dass Personen sich weniger mit Freunden im “realen Leben” verabreden.
Praktische Gründe
Irreversible Veränderungen sind bereits eingetreten oder betreffen vergangene Ereignisse.
- Beispiel I: Wie hat die Berichterstattung über 9/11 das Bild der Deutschen über Afghanistan geprägt?
- Beispiel II: Hat die Existenz von Suchmaschinen die Allgemeinbildung verändert?
Alternativen zur Prüfung kausaler Zusammenhänge
Korrelative Querschnittdesigns
Zusammenhang aufzeigen und Drittvariablen kontrollieren – aber: Ausschluss aller alternativen Erklärungen nicht möglich, keine Kontrolle über die Zeit
Zeitreihenanalysen (Längsschnittstudien)
Erfassen dieselben Daten zu mehreren Zeitpunkten; kann zeitliche Abfolge erfassen – aber: nicht alle alternativen Erklärungen ausschließbar
Beispiel aus der Kommunikationswissenschaft
Diese Bilder und eine schriftliche Variante des Trolley-Problems wurden in einer Studie von Grizzard et al.1 verwendet, um zu untersuchen, wie schemabasierte moralische Urteile (Held vs. Bösewicht) die Billigung von Verhaltensweisen (Hebel umlegen oder nicht) und nachfolgende moralische Urteile über Charaktere beeinflussen können (2x2 Experiment).
Hero Grizzard
Villain Grizzard
Die Ergebnisse
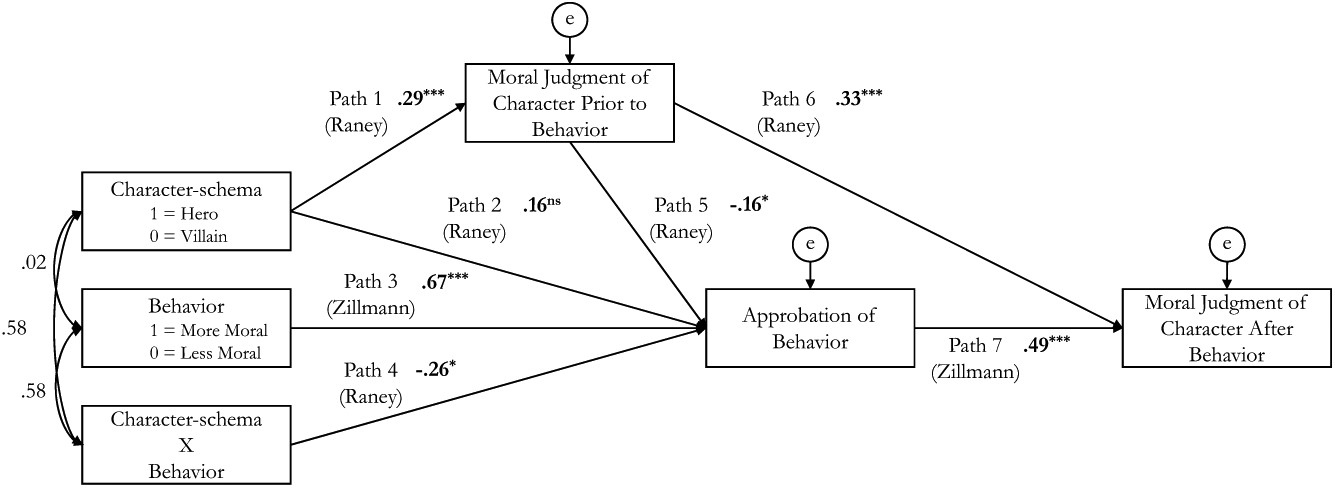
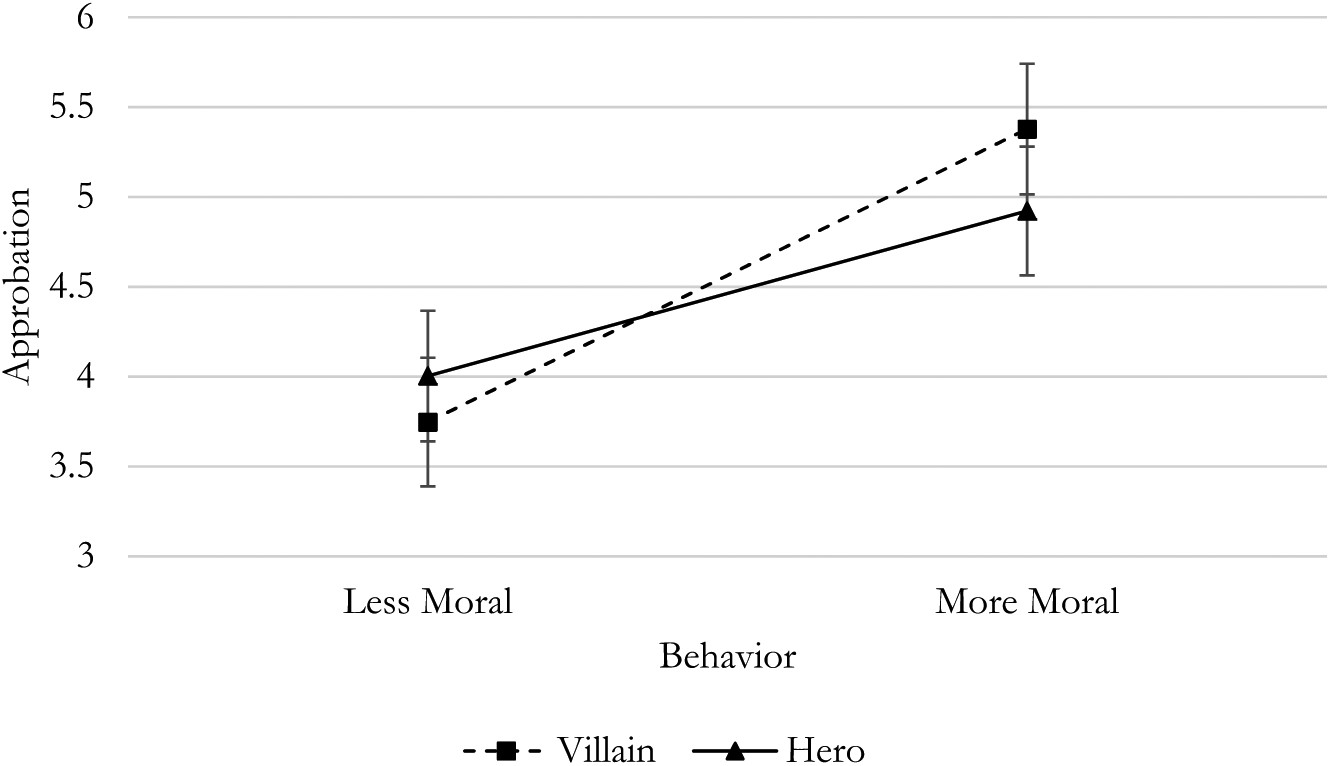
- Grizzard et al.1 zeigen, dass schemabasierte moralische Urteile (Held vs. Bösewicht) die Billigung von Verhaltensweisen und nachfolgende moralische Urteile über Charaktere beeinflussen können.
- Nachfolgestudie von Francemone et al.2 zeigt, dass schemabasierte Charakterurteile bei weiblichen und männlichen Figuren ähnlich ausgeprägt sind und der Effekt von Verhaltensweisen bei weiblichen Figuren sogar extremer ausfällt. Dies hat Implikaktionen für die Unterrepräsentation von weiblichen Hauptcharakteren in Narrativen.
Gruppenbildung
Siehe Aufgabe zu Sitzung 1 im Seminarplan
Bis zur nächsten Sitzung …
- Nachbereitung: Kap. 1 + 2 in Koch, T., Seeger, C., & Müller, P. (2025). Das Experiment in der Kommunikations- und Medienwissenschaft: Grundlagen, Durchführung und Auswertung experimenteller Forschung. Springer Fachmedien Wiesbaden. https://doi.org/10.1007/978-3-658-49131-4
- Vorbereitung: Kap. 4, 5, 11 in Koch, T., Seeger, C., & Müller, P. (2025). Das Experiment in der Kommunikations- und Medienwissenschaft: Grundlagen, Durchführung und Auswertung experimenteller Forschung. Springer Fachmedien Wiesbaden. https://doi.org/10.1007/978-3-658-49131-4
Sitzung 02: Validität, Designs, Ethik

Ressourcen für diese Sitzung
Agenda
- Gruppenzuteilung
- Validität und Varianten von Experimenten
- Experimentelle Designs und Manipulation
- Ethik in der experimentellen Forschung
Gruppenzuteilung
Validität und Varianten
Was bedeutet Validität?
- Validität bezeichnet die Gültigkeit der Befunde, die in einem Experiment ermittelt werden – wird tatsächlich das untersucht, was untersucht werden soll?
- Interne Validität bezieht sich auf die Gültigkeit der Befunde im vorgegebenen und kontrollierten Kontext der Untersuchung (→ Konstanthalten von Störvariablen). Eine hohe interne Validität ist dann gegeben, wenn sich Veränderungen angesichts der Kontrolle von Störvariablen eindeutig auf die Manipulation der UV zurückführen lassen.
- Externe Validität bezieht sich auf die Gültigkeit der Befunde über die spezifischen Rahmenbedingungen (→ Stichprobe, Stimuli etc.) eines Experiments hinaus und damit die Realitäts- bzw. Alltagsnähe des experimentellen Settings. Eine hohe externe Validität ist dann gegeben, wenn die experimentelle Versuchsanordnung den realen Gegebenheiten der untersuchten Zusammenhänge möglichst nahekommt.
Interne vs. externe Validität: Grizzard et al.
Aufgabe (~5 Minuten)
Denken Sie an das Grizzard-Experiment aus Sitzung 1:
- Wie war die interne Validität des Experiments zu bewerten? Welche Maßnahmen haben dazu beigetragen?
- Wie war die externe Validität einzuschätzen? Welche Einschränkungen gibt es?
- Was wiegt in diesem Fall schwerer – interne oder externe Validität? Warum?
Tauschen Sie sich mit Ihren Sitznachbar:innen aus.
Die Gretchenfrage
- In der Praxis geht höhere interne Validität oft zulasten externer Validität und umgekehrt.
- Auf welchen Aspekt mehr Wert gelegt werden sollte, kann nicht pauschal beantwortet werden; im wissenschaftlichen Diskurs gibt es Hardliner für beide Seiten.
- Letztlich ist es eine Abwägungssache:
- Was wird den Fragestellungen am ehesten gerecht?
- Wie viele Studien gibt es bereits zu einem Thema? (bei neuen Phänomenen: eher Fokus auf interne Validität)
- Validität kann in unterschiedlichen Bereichen eines Experiments unterschiedlich gelagert sein (z.B. Stichprobe, Stimulus, Durchführungskontext)
„Interne und externe Validität stehen in einem hydraulischen Verhältnis, sprich strenge Kontrolle und Elimination von Störvariablen geht oft zulasten der Generalisierung bzw. Realitätsnähe und umgekehrt.” 1
Experiment-Varianten: Labor- vs. Feldexperiment
Laborexperiment
- Durchführung in eigens dafür eingerichteten Räumlichkeiten, die (weitestgehend) kontrollierten Ablauf sicherstellen und konstante Rahmenbedingungen für alle Probanden ermöglichen.
- I.d.R. hohe interne Validität und relativ eindeutiger Kausalschluss möglich.
Feldexperiment
- Durchführung in der natürlichen Umgebung der Probanden, die die Umgebung des untersuchten Sachverhalts in der sozialen Realität widerspiegelt.
- I.d.R. hohe externe Validität und weniger Sicherheit für Kausalschluss, da geringere Kontrolle von Störvariablen.
Keine Dichotomie: graduelle Abstufungen sind möglich.
Experiment-Varianten: Online-Experiment
Experimentelle Befragungen/Beobachtungen …
- … mit dem Internet als reinem Verbreitungsweg.
- … mit dem Internet bzw. Online-Phänomenen als Untersuchungsgegenstand
(≙ Feldexperiment).
Vorteile
- Kostengünstig, aufwandsarm, schnell durchführbar
- Ortsunabhängig, automatische Datenspeicherung
- Vermeidung potenzieller Störquellen (z.B. Versuchsleitereffekte)
Nachteile
- Keine Kontrolle über die Situation der Teilnahme (zu Hause? Im Bus?)
- Keine Kontrolle über die Rezeption des Stimulus
- Keine Kontrolle über die ordnungsgemäße Aufklärung
Experiment-Varianten: Quasi-Experiment
Experimentelle Untersuchungsanlagen …
- … bei denen keine aktive Manipulation vorgenommen wird.
- … bei denen Störvariablen nicht ausreichend kontrolliert werden können (z.B. wenn Zuteilung zu Experimental- & Kontrollgruppe nicht randomisiert).
Trifft v.a. auf Feldexperimente zu, bei denen die UV nicht aktiv manipuliert werden kann
→ z.B. Auswirkungen von natürlich auftretenden Ereignissen.
Achtung
Die Bezeichnung wird teilweise auch für Untersuchungsanlagen ohne Vergleichsbedingung/Kontrollgruppe verwendet – davon sollte abgesehen werden!
Experimentelle Designs und Manipulation
Eine Frage des Designs
Das Experimentaldesign entscheidet über die Wahl des Vergleichsmaßstabs, d.h. darüber, wie die Variation einer UV im Experiment angelegt wird.
Grundidee des Experiments: Vergleich von (mind.) zwei Konditionen einer UV hinsichtlich einer AV. Dazu sind zwei Messungen der AV notwendig, wofür es verschiedene Optionen gibt:
- Messung in mehreren Gruppen zu einem Messzeitpunkt → Between-Subject Design
- Messung in einer Gruppe zu mehreren Messzeitpunkten → Within-Subject Design
- Messung in mehreren Gruppen zu mehreren Messzeitpunkten → Mixed Design
Between-Subject Design
- Gängigstes Design in der Kommunikationswissenschaft
- Design mit ungleichen Versuchsgruppen, d.h. mindestens zwei voneinander unterschiedliche Gruppen von Personen (i.d.R. Experimentalgruppe(n) und Kontrollgruppe)
- Manipulation erfolgt zwischen den Gruppen
- Messung der AV in der Kontrollgruppe dient als Vergleichsmaßstab (Baseline) für die Messung der AV in der/den Experimentalgruppe/n
- Auch Vergleich mehrerer Experimentalgruppen möglich (d.h. Design ohne Kontrollgruppe)
Beispiel: Beeinflusst der Feed-Typ die Stimmung nach der Nutzung?
| Gruppe | Feed | Inhalt | T1 | T2 |
|---|---|---|---|---|
| EG | Algorithmus | – | ✓ | – |
| KG | Chronologisch | – | ✓ | – |
| – | – | – | – | – |
| – | – | – | – | – |
Within-Subject Design
- Ein-Gruppen-Design: eine gleichbleibende Gruppe von Personen und Messwiederholung zu verschiedenen Zeitpunkten
- Manipulation erfolgt innerhalb derselben Gruppe von Versuchspersonen
- Häufigste Form: Vorher-Nachher-Messung (pretest-posttest design)
- Unterscheidet sich die Vorher-Messung von der Nachher-Messung, können Unterschiede auf den Stimulus zurückgeführt werden – vorausgesetzt Störfaktoren in der Zwischenzeit können ausgeschlossen werden
Vorteile: Konstante Gruppe; geringere Sample-Größe
Nachteile: Reihenfolge-, Ermüdungs-, Lerneffekte
Beispiel: Beeinflusst der Feed-Typ die Stimmung nach der Nutzung?
| Gruppe | Feed | Inhalt | T1 | T2 |
|---|---|---|---|---|
| VP (alle) | Algo & Chron | – | ✓ | ✓ |
| – | – | – | – | – |
| – | – | – | – | – |
| – | – | – | – | – |
Alle VP sehen beide Feed-Typen (T1 vs. T2), Reihenfolge rotiert.
Mixed Design
- Einsatz v.a. bei Experimentalstudien mit vielen Experimentalfaktoren, um Sample-Größe zu reduzieren.
- Meist Kombination von Between-Subject-Faktoren und Within-Subject-Faktoren.
- Vergleich unterschiedlicher Personengruppen (Between-Subject) mit einer mehrfachen Messung der AV (Within-Subject).
- Ermöglicht die Beobachtung von Veränderungen über die Zeit (→ Längsschnittstudien).
Beispiel: Beeinflusst der Feed-Typ die Stimmung nach der Nutzung?
| Gruppe | Feed | Inhalt | T1 | T2 |
|---|---|---|---|---|
| EG | Algorithmus | – | ✓ | ✓ |
| KG | Chronologisch | – | ✓ | ✓ |
| – | – | – | – | – |
| – | – | – | – | – |
Between: Feed-Typ. Within: Messzeitpunkt (vor/nach).
Ein Faktor, mehrere Stufen
- Bei Designs mit nur einer UV können auch mehr als zwei Gruppen miteinander verglichen werden → einfaktorielles Design mit n Faktorstufen.
- Bei Between-Subject Designs: höherer Aufwand, da zusätzliche Personengruppen benötigt werden.
- Bei Within-Subject Designs: zusätzliche Treatment- und Messzeitpunkte erhöhen Anfälligkeit für Reihenfolgeeffekte → dem kann durch zufällige/gezielte Rotation oder Lateinisches Quadrat begegnet werden.
Beispiel: Beeinflusst der Feed-Typ die Stimmung nach der Nutzung?
| Gruppe | Feed | Inhalt | T1 | T2 |
|---|---|---|---|---|
| EG 1 | Algorithmus 1 | – | ✓ | – |
| EG 2 | Algorithmus 2 | – | ✓ | – |
| KG | Chronologisch | – | ✓ | – |
| – | – | – | – | – |
3 Gruppen → 3 paarweise Vergleiche möglich.
Mehrere Faktoren, mehrere Stufen
- UV können auch mehrfaktoriell konzipiert werden, d.h. mehr als eine UV auf zwei Faktorstufen oder mehr vergleichen.
- Darstellung in einer Ziffernfolge, z.B. 3×2-Design bei Variation der UVA auf drei Stufen und der UVB auf zwei Stufen.
- Theoretisch beliebig viele Faktoren und Faktorstufen denkbar; wird aber schnell aufwändig in der Umsetzung.
- Auch unvollständige Designs sind möglich, wenn z.B. nicht alle Faktorkombinationen Sinn machen und Interaktionseffekte nicht im Zentrum des Forschungsinteresses stehen.
Beispiel: Beeinflusst der Feed-Typ die Stimmung nach der Nutzung?
| Gruppe | Feed | Inhalt | T1 | T2 |
|---|---|---|---|---|
| EG 1 | Algorithmus 1 | Musik | ✓ | – |
| EG 2 | Algorithmus 1 | Film | ✓ | – |
| EG 3 | Algorithmus 2 | Musik | ✓ | – |
| EG 4 | Algorithmus 2 | Film | ✓ | – |
| EG 5 | Chronologisch | Musik | ✓ | – |
| EG 6 | Chronologisch | Film | ✓ | – |
Warum mehrfaktorielle Designs?
- Manipulation zusätzlicher Faktoren verleiht zusätzliche Erklärungskraft, die aus dem Zusammenwirken der Faktoren entsteht.
- Haupteffekte beschreiben die alleinige Wirkung eines Faktors auf eine AV.
- Interaktionseffekte beschreiben Wechselwirkungen mehrerer Faktoren, d.h. Effekte, die durch das Zusammentreffen bestimmter Ausprägungen der untersuchten Faktoren auftreten.
- Zusätzlich manipulierte Faktoren werden als Moderatoren bezeichnet.
Beispiel: Beeinflusst der Feed-Typ die Stimmung nach der Nutzung?
| Gruppe | Feed | Inhalt | T1 | T2 |
|---|---|---|---|---|
| EG 1 | Algorithmus | Musik | M=5.8 | – |
| EG 2 | Algorithmus | Film | M=4.2 | – |
| EG 3 | Chronologisch | Musik | M=3.9 | – |
| EG 4 | Chronologisch | Film | M=5.3 | – |
AV: Stimmung (1–7). Algorithmus↑ Musik; Chronologisch↑ Film → Interaktion.
Manipulation im Experiment: Grundlegendes
- Manipulation unterscheidet experimentelle von nicht-experimenteller Forschung
- Mind. zwei Varianten einer UV werden kreiert und den Versuchspersonen vorgelegt → aktiver Eingriff in den Alltag.
- Treatment = konkrete Umsetzung der Manipulation (z.B. Veränderung des Gesichtsausdrucks).
- Stimulus = „Träger” der Manipulation, d.h. das, was die Probanden zu sehen/hören/lesen bekommen (z.B. eine Kurzgeschichte).
Hinweis
Bei der Ausgestaltung von Stimulus und Treatment ist stets große Sorgfalt geboten – eine Manipulation muss das gewünschte Konstrukt und nur dieses variieren!
Arten experimenteller Manipulation
- Instruktionsbasierte Manipulation: Variation in den Versuchsanweisungen; hohe interne Validität
- Umweltbasierte Manipulation: Variation in der Umgebung der Probanden (z.B. Veränderung der Raumtemperatur, Ausstattung, Lautstärke etc. bei Laborexperimenten)
- Soziale Manipulation: Variation durch Anwesenheit und/oder Verhalten anderer Personen (z.B. Versuchsleiter, Dritte); hohe externe Validität
- Manipulation mittels Stimulus: Variation durch Vorlage verschiedener verbaler, audiovisueller oder schriftlicher Inhalte; häufigste Art in der KoWi
Mischformen der vier Typen sind möglich, z.B. instruktions- und stimulus-basiert oder sozialbasiert und stimulus-basiert.
Manipulationscheck
Um festzustellen, ob eine Manipulation überhaupt gelungen ist, benötigen wir i.d.R. einen Manipulationscheck bzw. Treatmentcheck.
Bei experimentellen Befragungen: üblicherweise spezielle Fragen/Aufgaben, um zu testen, ob Versuchspersonen die Manipulation wie intendiert wahrgenommen haben. Je nach Art der Manipulation unterschiedliche Fragetypen:
- Aufmerksamkeits-/Erinnerungsfragen, z.B. wenn bestimmte Elemente im Stimulus vorhanden oder nicht vorhanden sind (→ “Es war ein Mann zu sehen”)
- Subjektive Einschätzungsfragen, z.B. wenn die Ausprägung/Intensität eines bestimmten Aspekts manipuliert wird (→ “Der Charakter wirkte auf mich wie ein Held”)
Ebenfalls sinnvoll hinsichtlich interner Validität: Test auf potenzielle Konfundierung durch zusätzliche Abfragen, die sich in den Gruppen idealerweise nicht unterscheiden (→ “Der Charakter war gutaussehend”).
Pretest
- V.a. bei erstmaliger Nutzung eines Stimulus bzw. einer Manipulation ist es sinnvoll, die Eignung vorab in einer separaten Untersuchung zu testen → Pretest.
- Mit einem Pretest kann zudem ein häufiges Problem von Manipulationschecks umgangen werden, nämlich die Sensibilisierung von Versuchspersonen für das Untersuchungsziel (je nach Platzierung im Fragebogen).
Wichtig
Personen, die am Pretest teilgenommen haben, sollten später nicht mehr beim eigentlichen Experiment teilnehmen, da sie den Stimulus dann bereits kennen.
Medieninhalte als Stimuli
In der KoWi wird häufig mit Medieninhalten als Stimuli in Experimenten gearbeitet. Damit gehen eine Reihe von Herausforderungen einher:
Spannungsverhältnis von interner und externer Validität, z.B. bei der Verwendung „echter” Medieninhalte
Mangelnde Verallgemeinerbarkeit: Selektion, Zuschnitt und Umfang von Medieninhalten als Stimuli werden oft nicht der Komplexität realer Medienrezeption gerecht (z.B. kurze Film-Ausschnitte bei Fragestellungen, die sich auf ein ganzes Genre beziehen)
Bei fiktiven Stimuli ethische Herausforderungen und Probleme mit Künstlichkeit und Wahrnehmung der Probanden. Speziell bei Forschung über Online-Umgebungen: sozialer Kontext und Interaktivität kann in Stimuli i.d.R. kaum abgebildet werden.
„Man darf nicht der falschen Vorstellung aufsitzen, man müsste alle Validitätsprobleme in einem Einzelexperiment lösen. […] Jedes Experiment ist ein einzelner Baustein, der zur Beantwortung einer größeren Forschungsfrage beiträgt.” 1
Ethik in der experimentellen Forschung
Warum spielt Ethik eine Rolle?
- Bei allen Arten des sozialwissenschaftlichen Experiments arbeiten wir mit Menschen.
- Gleichzeitig basiert Experimentalforschung auf einer bewussten Manipulation menschlicher Kognitionen / Emotionen / Verhaltensweisen.
- Daraus erwächst eine besondere Verantwortung:
- Wohlergehen, Rechte, Interessen der Probanden müssen berücksichtigt werden.
- Es darf kein nachhaltiger Schaden für Versuchspersonen, Fachgemeinschaft und Wissenschaft allgemein entstehen.
Forschungsethische Grundprinzipien
- In jede Form von experimenteller Forschung sollten von Beginn an forschungsethische Überlegungen einfließen.
- Orientierung bieten Ethik-Kodizes von Fachgesellschaften (z.B. DGPuK) oder Ethik-Kommissionen an Universitäten – entsprechende Voten werden immer häufiger für die Publikation von Studien vorausgesetzt.
Utilitaristische Position
Handlungen sind moralisch gut, wenn sie den Gesamtnutzen / das Wohlergehen aller Beteiligten nicht verringern bzw. möglichst erhöhen. → Einsatz von fiktiven Stimuli und Manipulation gerechtfertigt, wenn sie aufgeklärt wird (Debriefing) und der Erkenntnisgewinn überwiegt.
Deontologische Position
Betrachtet nicht nur die Konsequenzen einer Handlung, sondern die Handlung selbst; alle unmoralischen Handlungen (z.B. Lügen) sind unter allen Umständen zu unterlassen. → Einsatz von fiktiven Stimuli und Manipulation nicht gerechtfertigt.
Forschungsethik: Freiwilligkeit und Einwilligung
Freiwilligkeit der Studienteilnahme sicherstellen
- Erzwungene (z.B. im Lehrkontext) und unbewusste Teilnahme (z.B. bei Feldexperimenten) vermeiden.
- Informierte Einwilligung / Briefing: Vorab-Aufklärung über Forschungszweck, Dauer, Vorgehensweise, potenzielle Risiken, Gewährleistung der Vertraulichkeit, Möglichkeiten zum Abbruch – oft nur eingeschränkt möglich, wenn interne Validität gewahrt werden soll.
- Stattdessen: Debriefing über Untersuchungszweck und vorgenommene Manipulation am Ende des Experiments.
- Wenn keine Schädigung entstehen kann, ist auch eine Täuschung (passiv oder aktiv) der Versuchspersonen legitim.
- Einsatz von Incentives/Anreizen zur Studienteilnahme aus ethischen Gesichtspunkten abwägen → Teilnahme aus finanzieller Notlage heraus vermeiden!
Forschungsethik: Schädigung vermeiden
Vermeiden einer Schädigung der Versuchspersonen
- Allgemein: Studienteilnahme soll keine physischen oder psychischen Schmerzen verursachen, ebenso wenig körperliche Schäden.
- KoWi: v.a. Risiko psychischer Schmerzen in sensiblen Bereichen der Wirkungsforschung (z.B. bei AVs wie Depressivität, Suizidalität, Selbstwert, soziale Ausgrenzung etc.) → Verwendung potenziell traumatisierender oder emotional aufwühlender Stimuli nur in Ausnahmefällen und unter expliziter Zustimmung.
- Beeinflussung von Kognitionen, Emotionen, Verhalten durch Studienteilnahme bzw. Stimulusrezeption gilt ebenfalls als Schädigung (→ Forschung zu Stereotypen oder Tabakkonsum).
Forschungsethik: Debriefing
Debriefing der Versuchspersonen
Essenziell! Dient zur Aufklärung über experimentelle Manipulation und mögliche Folgen sowie zur Bereitstellung ergänzender Informationen. Bei Laborexperimenten: schriftlich und ggf. mündlich; bei Online-Experimenten: schriftlich auf der letzten Seite des Fragebogens.
Inhalt sollte Aufschluss geben über:
- Untersuchungszweck und konkrete Forschungsfragen
- Ursprung/Quelle des Stimulusmaterials (v.a. bei fiktiven Inhalten)
- Richtigstellung unwahrer Informationen im Stimulus
- Offenlegung persuasiver Strategien zur Manipulation von Kognitionen, Emotionen und Verhalten
- Kontaktinformationen für Rückfragen
- Optionen zum Erhalt einer Ergebniszusammenfassung/-interpretation
Debriefing zwingt Forschende zur Rechtfertigung ihrer Untersuchungsanlage gegenüber den Versuchspersonen.
Forschungsethik: Vertraulichkeit und Datenschutz
- Grundrecht auf informationelle Selbstbestimmung achten → Personen müssen selbst über die Preisgabe und Verwendung personenbezogener Daten bestimmen können (im Zweifel: Datenschutzbeauftragte konsultieren).
- Datenerhebung bei Experimenten meist anonym (= keine Speicherung von personenbezogenen Informationen); darauf muss vorab/zu Beginn hingewiesen werden.
- Sofern Anonymität bei der Datenerhebung nicht möglich ist (z.B. bei Beobachtungsstudien wie Eye-Tracking), muss sichergestellt werden, dass die identifizierenden Rohdaten vertraulich behandelt werden und nur ausgewählten Personen zugänglich sind.
Soweit Fragen?
Sitzung 03: Eine Problemstellung entwickeln
Ressourcen für diese Sitzung
Agenda
- Open Science & Präregistrierung
- Themenschwerpunkt: Algorithmisch kuratierte Unterhalungsmediennutzung
- Entwicklung einer Problemstellung
Open Science

Ressourcen
Dienlin, T., Johannes, N., Bowman, N. D., Masur, P. K., Engesser, S., Kümpel, A. S., Lukito, J., Bier, L. M., Zhang, R., Johnson, B. K., Huskey, R., Schneider, F. M., Breuer, J., Parry, D. A., Vermeulen, I., Fisher, J. T., Banks, J., Weber, R., Ellis, D. A., … De Vreese, C. (2021). An Agenda for Open Science in Communication. Journal of Communication, 71(1), 1–26. https://doi.org/10.1093/joc/jqz052
Open Science Collaboration (2015). Estimating the Reproducibility of Psychological Science. Science, 349(6251), aac4716. https://doi.org/10.1126/science.aac4716
Open Science: Warum?
- Replikationskrise, v.a. in der Psychologie: Ein Großteil psychologischer Studien können nicht repliziert werden (Open Science Collaboration, 2015)
- Prominente Fälle von grobem wissenschaftlichem Fehlverhalten wie fabrizierten Daten (z.B. Diederik Stapel)
- Problem: fehlende Transparenz: Was wurde erhoben, manipuliert, ausgewertet?
- Bevorzugung signifikanter Ergebnisse im Veröffentlichungsprozess
- fragwürdige Forschungspraktiken (QRP – questionable research practices), um solche Ergebnisse zu erzielen
Beispiele für QRPs
- HARKing: Hypothesizing After Results are Known
- Hypothesen erst dann aufstellen, wenn die Ergebnisse bekannt sind
- p-Hacking
- Ergebnisdarstellung oder Datenanalysen so verändern, dass am Ende ein signifikantes Ergebnis herauskommt (z.B. durch selektives Berichten, Ausschluss bestimmter Teilnehmer:innen, Modelspezifizierungen, …)
- Menschliche Fehler
- Verschiedene Entscheidungen, die in der Studienkonzeption und Analyse getroffen werden (müssen)
- “Honest mistakes” in Datenanalysen
Ist das Vertrauen in die Wissenschaft in Gefahr?
- Was können wir tun?
- In der Kommunikationswissenschaft, siehe Dienlin et al. (2021)
Was können wir tun?
- Open Science als fachübergreifende Bewegung, um den wissenschaftlichen Forschungsprozess und seine Ergebnisse transparenter zu machen
- Grundprinzipien: Transparenz, Reproduzierbarkeit, Replizierbarkeit
- Open Science Praktiken:
- Präregistrierung: Vor dem Durchführen der Studie Hypothesen, Stichprobenziehung, Datenanalyseschritte etc. detailliert festhalten
- Teilen von Materialien: z.B. Fragebögen, Stimulusmaterial, Code der Datenauswertung, …
- Teilen der Daten

siehe auch siehe Dienlin et al. (2021) und https://osf.io/wpc8b
Präregistrierung: Was ist das?
- Präregistrierung: Detaillierte Festlegung von Hypothesen, Studiendesign, Stichprobenziehung, Datenanalyseschritten etc. vor Durchführung der Studie
- Ziel: Erhöhung der Transparenz und Reproduzierbarkeit von Forschungsergebnissen
- In der Praxis: Erstellung eines schriftlichen Dokuments, das die geplante Studie beschreibt und auf einer öffentlichen Plattform (z.B. OSF) hochgeladen wird
- Präregistrierung kann auch als Präanalyseplan bezeichnet werden, wenn der Fokus auf der Festlegung der geplanten Datenanalyseschritte liegt
Beispiel: Minimale Präregistrierung für ein Experiment auf AsPredicted: https://aspredicted.org/xk8et.pdf
Template für Präregistrierung auf OSF: https://doi.org/10.31222/osf.io/epgjd
Fragen?
Themenschwerpunkt: Algorithmisch kuratierte Unterhalungsmediennutzung
Besprechung der Literatur
Aufgabe (~30 Minuten)
Tauschen Sie sich in Ihrer Gruppe über die fünf Fragen zum Artikel von Nabi und van der Waal (2026) aus.
- Tragen Sie Ihre Antworten so zusammen, dass wir diese im Anschluss im Plenum diskutieren können.
- Dokumentieren Sie offene Fragen, Unklarheiten, Kritikpunkte, Anknüpfungspunkte für die Entwicklung einer Problemstellung.
Globaler Trend: Social-Media-Verbot für Jugendliche
🇦🇺 NPR · 10. Dez. 2025
Social-Media-Verbot für Kinder unter 16 tritt in Australien in Kraft
PM Albanese begrüßte es als „Familien, die sich die Macht von Big Tech zurückholen”. Eltern berichteten von verzweifelten Kindern, die ausgesperrt wurden – doch bereits einige 11-Jährige überlisteten Altersschätzungstools durch aufgemalte Barthaare.
🇩🇪 netzpolitik.org · 7. Apr. 2026
Social-Media-Verbot lässt Bundesregierung ahnungslos zurück
Obwohl Merz, Klingbeil und der Bundespräsident alle ein Verbot fordern, ergab eine parlamentarische Anfrage: Die Bundesregierung kann weder sagen, ob es wissenschaftlich gerechtfertigt noch verfassungsrechtlich verhältnismäßig wäre – oder ob sie überhaupt eines will.
🇫🇷 France 24 · 27. Jan. 2026
Französisches Parlament verabschiedet Gesetz zum Social-Media-Verbot für unter 15-Jährige
Die Nationalversammlung stimmte in einer nächtlichen Sitzung mit 130 zu 21 Stimmen. Macron nannte es einen „wichtigen Schritt”; die Durchsetzung ist ab September 2026 geplant – doch die EU-Kommission warnte, dass die Einhaltung letztlich in ihrer Zuständigkeit liege.
🇳🇴 The Next Web · 24. Apr. 2026
Norwegen plant Social-Media-Verbot für Kinder unter 16
Die Regierung hob die geplante Altersgrenze nach Auswertung von über 8.000 öffentlichen Eingaben von 15 auf 16 Jahre an – in Anlehnung an Australien statt an das DSGVO-Mindestalter der EU. Die Verantwortung für die Altersverifikation liegt klar bei den Plattformen.
🌍 TechCrunch · 23. Apr. 2026
Diese Länder planen ein Social-Media-Verbot für Kinder
Österreich (unter 14), Dänemark (unter 15), Malaysia, Portugal, Spanien, Polen, Slowenien – alle bewegen sich auf Verbote zu. Indonesien setzt eines bereits durch und hat Google und Meta vorgeladen.
🇩🇪 netzpolitik.org · 1. Apr. 2026
EU-Recht geht vor: Kein Spielraum für deutsches Social-Media-Verbot
Der wissenschaftliche Dienst des Bundestags kam zum zweiten Mal zu dem Schluss, dass das EU-Recht – vor allem der Vorrang des DSA und das Herkunftslandprinzip der E-Commerce-Richtlinie – Deutschland an einem nationalen Alleingang hindert.
Warum nutzen wir Medien, wenn es uns nicht gut geht?
Potentielle Gründe für Verbote (z.B. Zusammenhang mit mentaler Gesundheit1) oft komplex; außerdem viele potentiell positive Effekte von Mediennutzung in belastenden Situationen:
- Mood Management2: Mediennutzung als Strategie zur Regulierung negativer Stimmungen
- Selective Exposure3: Menschen wählen Inhalte, die ihrem aktuellen Bedürfnis entsprechen
- Aber: Wie ist das eigentlich in algorithmisch kuratierten Umgebungen, in denen Nutzer*innen nicht mehr selbst auswählen, sondern Inhalte vorgegeben bekommen?
- Erholung durch Medien4: Medien können psychologische Erholung nach Belastung fördern
Die entscheidende Frage ist nicht nur ob Medien helfen — sondern welche Inhalte in welchen Situationen wirksam sind.
Unterhaltungserleben: Mehr als nur Spaß
Unterhaltungsforschung unterscheidet zwei grundlegende Erlebnisdimensionen1:
| Hedonisch | Eudaimonisch | |
|---|---|---|
| Ziel | Vergnügen, Ablenkung | Bedeutung, Reflexion |
| Emotion | Freude, Belustigung | Elevation, Rührung, Hoffnung |
| Typische Inhalte | Comedy, Action | Drama, Dokumentation, Inspiration |
| Outcome | Stimmungsverbesserung | Sinnerleben, Wachstum |
Menschen suchen nicht immer das Angenehmste — sondern das Passende2.
Medien als Copingressource
Coping1: Bewältigungsstrategien bei Stress lassen sich unterscheiden in:
- Problemorientiertes Coping: Aktive Veränderung der Stresssituation
- Emotionsorientiertes Coping: Regulierung der emotionalen Reaktion auf die Situation
Übertragen auf Mediennutzung2 zum Beispiel:
- Kontrollierbare Stressoren → Inhalte, die Handlungsmotivation und Hoffnung stärken
- Unkontrollierbare Stressoren → Inhalte, die Entspannung und Ablenkung ermöglichen
Entscheidend: Die Wirksamkeit eines Inhalts hängt davon ab, wie gut er zur Bewältigungsanforderung der Situation passt (Optimal Matching3).
Media Prescriptions: Medien gezielt einsetzen
Grundidee1: Wenn bestimmte Medieninhalte nachweislich positive psychologische Effekte haben — kann man sie dann gezielt „verschreiben”?
Befunde aus der Forschungsgruppe um Nabi:
- Kurzvideos mit inspirierenden Inhalten erhöhen Hoffnung
- Hoffnung vermittelt Effekte auf Stressreduktion und Zielmotivation
- Diese Effekte zeigen sich auch bei kurzen täglichen Dosen (3–5 Min.)
- Nabi & van der Wal2: Nutzer*innen können sich Inhalte auch selbst auswählen mit vergleichbaren Effekten
Offene Frage: Bisherige Studien geben allen Teilnehmenden denselben Inhaltstyp — unabhängig von ihrer aktuellen Situation.
Das Matching-Problem: Der nächste Schritt
Bislang: Ein Inhaltstyp für alle → „One size fits all”
Neue Frage: Sollten verschiedene Situationen unterschiedliche Inhalte erhalten?
Kernhypothese: Situativ passende Inhalte wirken stärker als objektiv positive, aber situativ unpassende Inhalte.
Unser Forschungsprojekt: Überblick
Ziel: Entwicklung und Testung eines situativen Matching-Algorithmus für Kurzvideos — eingebettet in eine naturalisitische Nutzungssituation.
Kernelement: Eine eigens entwickelte App, in der Teilnehmende täglich kurze Videos schauen. Vor und nach jeder Session beantworten sie Fragen zur aktuellen Situation und zum Erleben.
Heute: Sie entwickeln in Gruppen eigene Forschungsfragen, die sich in dieses Projekt einfügen könnten.
Soweit Fragen?
Im Anschluss: Gruppenarbeit
(siehe Aufgabe zur heutigen Sitzung).
Abgabe des Zwischenstandes per Mail (1x pro Gruppe) bis spätestens Sonntag, 03.05.2026
Sitzung 04: Computational Methods
Ressourcen für diese Sitzung
Agenda
- Simulation & Power
- Computergestützte Methoden bei der Stimulusentwicklung / -selektion
- Vibe Coding
Monte-Carlo-Simulation
Bei der Versuchsplanung ist es oft sinnvoll, vorab künstliche Daten zu generieren, um das Design und die statistische Auswertung zu validieren.
Einfaches Between-Subjects-Design
Wir simulieren zwei Gruppen (ad_type: “funny” vs. “not funny”).
Mit sim_design() aus dem faux-Paket erzeugen wir Daten mit unterschiedlichen Mittelwerten (mu) und einer Stichprobengröße von n=50.
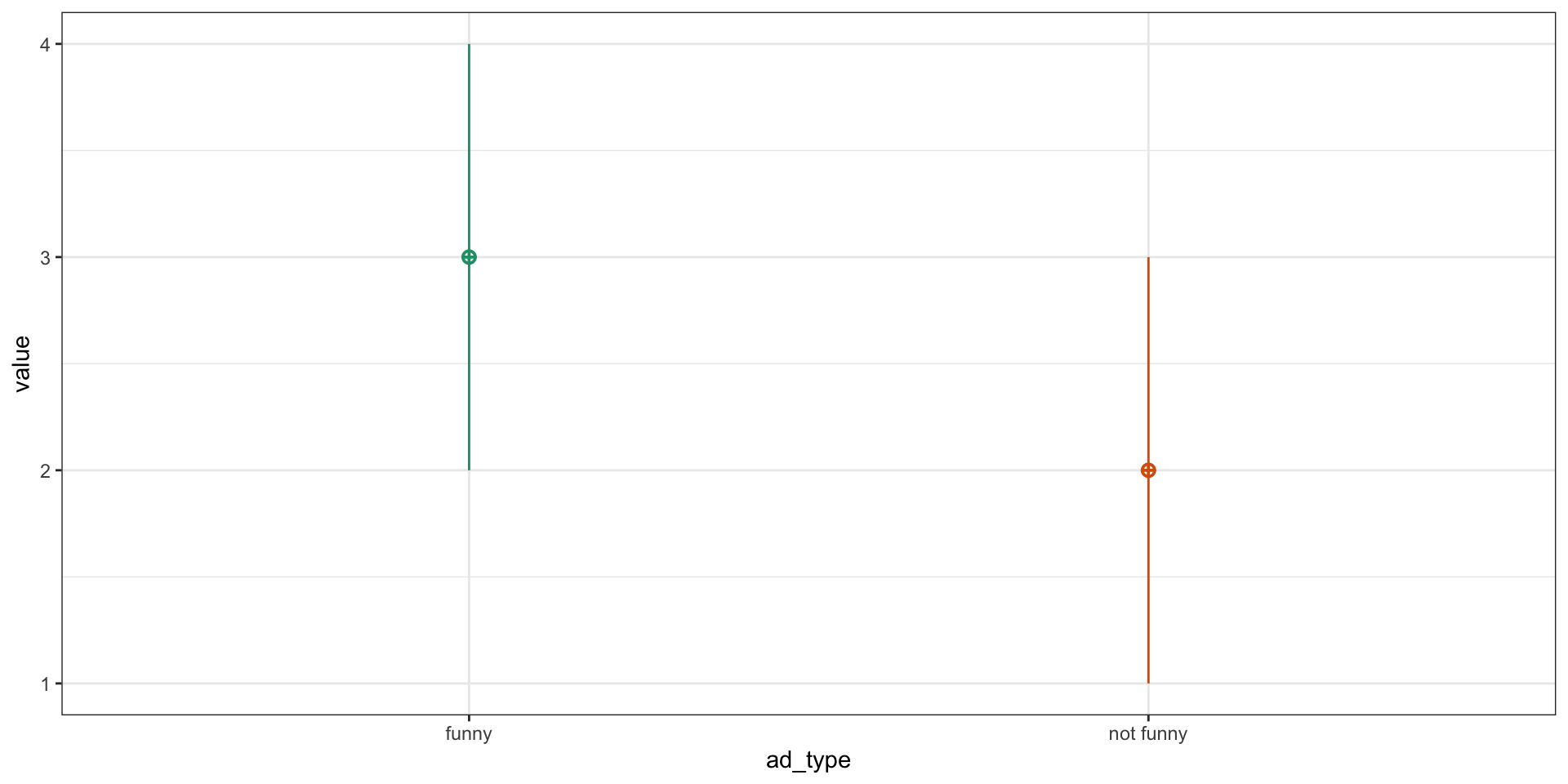
Einfaches Between-Subjects-Design
Wir simulieren zwei Gruppen (ad_type: “funny” vs. “not funny”).
Mit sim_design() aus dem faux-Paket erzeugen wir Daten mit unterschiedlichen Mittelwerten (mu) und einer Stichprobengröße von n=50.
# A tibble: 100 × 3
id ad_type y
<chr> <fct> <dbl>
1 S001 funny 0.999
2 S002 funny 3.33
3 S003 funny 4.17
4 S004 funny 5.06
5 S005 funny 1.62
6 S006 funny 1.85
7 S007 funny 2.29
8 S008 funny 1.95
9 S009 funny 2.35
10 S010 funny 2.81
# ℹ 90 more rows# A tibble: 2 × 3
ad_type mean sd
<fct> <dbl> <dbl>
1 funny 3.01 0.988
2 not funny 1.97 1.05 Überprüfung mit t-Test
Welch Two Sample t-test
Parameter | Group | Mean_Group1 | Mean_Group2 | Difference | 95% CI
---------------------------------------------------------------------------
y | ad_type | 3.01 | 1.97 | 1.04 | [0.63, 1.44]
Parameter | t(97.59) | p | d | d CI
---------------------------------------------------
y | 5.07 | < .001 | 1.03 | [0.60, 1.45]
Alternative hypothesis: two.sidedDer t-Test bestätigt den simulierten Unterschied zwischen den Gruppen.
Power-Analyse
Power (Teststärke) = Wahrscheinlichkeit, einen Effekt einer bestimmten Größe statistisch signifikant nachzuweisen, wenn dieser Effekt in der Population tatsächlich vorhanden ist
(d.h. H₀ korrekt abzulehnen, 1 − β).
Wir verpacken Simulation und t-Test in eine Funktion und wiederholen diese 100-mal mit replicate().
# A tibble: 5 × 1
value
<dbl>
1 0.0109
2 0.0314
3 0.0574
4 0.0000451
5 0.00515 Interpretation
Bei n = 10 pro Gruppe beträgt die geschätzte Power ca. 49% – d.h. nur in etwa jeder zweiten Studie mit dieser Stichprobengröße würde der tatsächliche Effekt signifikant gefunden.
Für eine Power von 80% ist eine größere Stichprobe nötig. Power-Analyse für verschiedene n:
Komplexere Designs und agentenbasierte Simulationen
Siehe: https://stats.ifp.uni-mainz.de/ba-ccs-track/exp-simulation.html
Behalten Sie die Überlegungen bei der Bestimmung der Stichprobengröße im Hinterkopf, wenn Sie Ihre eigene Studie planen!
Für agentenbasierte Ansätze mit LLMs, siehe den aktuellen wissenschaftlichen Diskurs, z.B.:
Binz, M., Akata, E., Bethge, M., Brändle, F., Callaway, F., Coda-Forno, J., Dayan, P., Demircan, C., Eckstein, M. K., Éltető, N., Griffiths, T. L., Haridi, S., Jagadish, A. K., Ji-An, L., Kipnis, A., Kumar, S., Ludwig, T., Mathony, M., Mattar, M., … Schulz, E. (2025). A Foundation Model to Predict and Capture Human Cognition. Nature, 644(8078), 1002–1009. https://doi.org/10/g9r4fm
Cummins, J., Elson, M., & Hussey, I. (2025). Cognitive Dissonance in Large Language Models Is Neither Cognitive nor Dissonant. Proceedings of the National Academy of Sciences, 122(35), e2517912122. https://doi.org/10/g9zp53
Schröder, S., Morgenroth, T., Kuhl, U., Vaquet, V., & Paaßen, B. (2025, August 13). Large Language Models Do Not Simulate Human Psychology. https://doi.org/10.48550/arXiv.2508.06950
Soweit Fragen?
Computergestütze Methoden bei der Stimulusentwicklung
Das Problem: Stimuli als vernachlässigte Ressource
Reeves et al.1 analysierten 306 Experimente aus Media Psychology und hochzitierten Medienstudien:
- Studien investieren in zehntausende Versuchspersonen – aber nur in winzige Stimulussamples
- 65% der Experimente verwendeten pro Bedingung nur ein einziges Medienstimulus-Beispiel
- Die verwendeten Medieninhalte sind weniger variabel, nuanciert und idiosynkratisch als Medien in der realen Welt
- Stimuli repräsentieren dadurch oft nicht die Breite realer Medienerfahrungen, über die Autoren generalisieren
Stimuli sollten wie Stichproben behandelt werden – mit Blick auf Repräsentativität, Varianz und Stichprobengröße.
Lösungsansätze bei Reeves et al.
- Statistische Lösungen: Medienstimuli als Random Factors modellieren (z.B. Mixed Models), um Variabilität zwischen Stimuli zu berücksichtigen
- Single-Subject-Designs: Intraindividuelle Daten über viele Stimuli hinweg – individuelle Modelle statt Gruppenvergleiche
- Stimulus-intensive Designs: Fokus auf die Gesamtheit der Medieninhalte, die Personen rezipieren, nicht nur Stichproben
LLMs als Werkzeug zur Stimulusentwicklung / -selektion
Große Sprachmodelle (LLMs) können das Stimulusproblem gezielt adressieren:
- Skalierung: Automatisierte Generierung oder Selektion von Dutzenden bis Hunderten von Stimulusvarianten – z.B. Kurzvideoüberschriften, Social-Media-Posts, Artikel – mit kontrollierten Variationen (Ton, Framing, Länge)
- Kontrolle: Gezielte Manipulation einzelner Merkmale (z.B. Emotionalität, Valenz, Komplexität) bei gleichzeitiger Konstanthaltung anderer Eigenschaften
- Idiosynkrasie: Generierung oder Selektion personalisierter Stimuli, die realen, individualisierten Medienerfahrungen ähneln – besonders relevant für Matching-Experimente
- Transparenz & Replikation: Prompt-basierte Stimuluserstellung ist dokumentierbar und (größtenteils) reproduzierbar
Wichtige Einschränkung:
- LLM-generierte Stimuli müssen auf externe Validität geprüft werden – sind sie wirklich repräsentativ für reale Medieninhalte?
- LLM-selektierte Stimuli müssen auf interne Validität geprüft werden – erfüllen sie die intendierten Merkmale (z.B. emotionaler Ton)?
Soweit Fragen?
Stimulusselektion mit LLMs für situatives Matching
Inhaltliche Ähnlichkeit
Embedding Similarity: LLMs können Inhalte in einen mehrdimensionalen Raum einbetten, in dem ähnliche Inhalte näher beieinander liegen.
- Beispiel: Berechnung der Kosinusähnlichkeit zwischen einem Nutzerprompt (z.B. „Ich hatte heute Stress auf der Arbeit”) und potenziellen Stimuli (z.B. Kurzvideo-Transkripte) → Auswahl derjenigen Stimuli, die am besten zum aktuellen Bedürfnis passen
- Berücksichtigung von Nuancen und Kontext, die über einfache Schlüsselwortübereinstimmungen hinausgehen
Inhaltsklassifikation
LLMs können Inhalte anhand von vordefinierten Kriterien klassifizieren (z.B. emotionaler Ton, Thema, Genre).
- Beispiel: Ein Prompt wie „Klassifiziere dieses Video als hedonisch oder eudaimonisch” → LLM weist jedem Stimulus eine Kategorie zu → gezielte Auswahl von Stimuli, die bestimmte Erlebnisdimensionen ansprechen
- Ermöglicht die gezielte Manipulation von Stimulusmerkmalen, um spezifische Effekte zu testen (z.B. Wirkung von hedonischen vs. eudaimonischen Inhalten in unterschiedlichen Situationen)
Welche Methode (Ähnlichkeit vs. Klassifikation) besser geeignet ist, hängt von der spezifischen Forschungsfrage und den verfügbaren Stimuli ab – möglicherweise ist auch eine Kombination beider Ansätze sinnvoll. Validierung immer notwendig!
Soweit Fragen?
Vibe Coding
Was ist Vibe Coding?
- Softwareentwicklung in natürlicher Sprache – KI übernimmt die technische Umsetzung (z.B. Cursor, GitHub Copilot, Replit Agent)
- Rolle der Menschen: konzeptueller Impulsgeber statt aktiver Kodierer
- Potenziale: schnelles Prototyping, niedrige Einstiegshürde, iteratives Arbeiten
- Risiken: mangelnde Codequalität, Sicherheitslücken, sinkendes Systemverständnis, Halluzinationen
- Für UX und Stimulusentwicklung hilfreich: What you see is what you get – Oberflächen und Prototypen lassen sich schnell visualisieren und mit Zielgruppen validieren
Vorsicht bei der Datenanalyse
Vibe Coding unbeaufsichtigt für statistische Analysen einzusetzen ist riskant: KI-generierter Analysecode kann fehlerhafte Berechnungen, falsche Modellspezifizierungen oder erfundene Methoden enthalten – immer kritisch prüfen!
Gruppenarbeit
Feedback und Weiterarbeit an der Präregistrierung
Sitzung 13: Semesterabschluss und Informationen zum Projektbericht

Ressourcen für diese Sitzung
Agenda
- Informationen zum Projektbericht
- Evaluation
- Abschlusspräsentationen
- Gruppen-Sprechstunden nach Bedarf
Informationen zum Projektbericht
- Die Kennzeichnung der eigenen Arbeitsleistung ist verpflichtend
- CRediT-Statement (https://credit.niso.org)
- Verpflichtend: Conceptualization, Methodology, Formal analysis, Writing – original draft, Writing – review & editing
- Weitere Angaben falls zutreffend
- z.B. Conceptualization (FD, RK, AG); Methodology (FD); …
- Bei einer strikten Aufteilung der Kapitel unter den Teammitgliedern sollte eine finale Überarbeitung vorgenommen werden, damit die einzelnen Teile ineinandergreifen
- Abgabe einer elektronischen Version (PDF) über die Abgabefunktion im LMS (“Abgabe der Hausarbeit”) — es genügt eine Abgabe pro Gruppe
- Ergänzende Materialien (Analyseskripte, Quarto-HTML Output, etc.) als .zip-Datei verpacken und hochladen
- Formalia gibt es hier: https://ifp.uni-mainz.de/seminar-und-abschlussarbeiten/
Inhaltliche Vorgaben
- ca. 5 Seiten pro Gruppenmitglied, ca. 7000-9000 Wörter (ca. 20-25 Seiten) insgesamt
- Seitenanzahl ist nur eine grobe Orientierungshilfe
- Es gilt Qualität vor Quantität, d. h. adäquate Behandlung des Themas sowie angemessene Analyse der Daten und Einordnung der Ergebnisse
- Wichtige Grafiken und Tabellen in den Text, ergänzende Analysen in den Anhang
- Hausarbeit sollte die folgenden Punkte enthalten: Einleitung, Theorie-/Literaturteil, Methoden, Ergebnisse, Diskussion
- Orientieren Sie sich bei Struktur und Aufbau an aktuellen Publikationen
- Dokumentation der eigenen Arbeit, d. h. bereits vorhandene Materialien können recycled werden
- Es muss nichts “rauskommen”, Lernen und Üben im Fokus
- Formalien und Regeln wissenschaftlicher Arbeit sind wichtig und notenrelevant
Einsatz von KI-Tools in der Hausarbeit
Dokumentation im Methodenteil (nicht im Anhang)
- Nutzung von KI-Modell zur Klassifikation & Selektion von Stimuli
Außerdem erlaubt (wenn im Anhang dokumentiert)
- KI-Nutzung zur Recherche von Literatur (z. B. Elicit, ResearchRabbit)
- KI-Nutzung zur Überarbeitung des Textes (z. B. DeepL Write)
- KI-Nutzung zur unterstützten Datenanalyse (z. B. ChatGPT, KI-Chat Uni Mainz)
In diesem Kurs nicht erlaubt
- KI zur Generierung des Hausarbeitstextes (z. B. ChatGPT)
Angebote der JGU
Campusweite Schreibwerkstatt
- https://www.schreibwerkstatt.uni-mainz.de/
- Individuelle Schreibberatung:
- Zeitmanagement, Schreibstrategien, Lesestrategien, Textfeedback und Überarbeitungsstrategien, Selbstreflexion
Soweit Fragen?
Evaluation

https://befragung.uni-mainz.de/evasys/online/
FPUE2Literaturangaben
Nabi, R. L., & Van Der Wal, A. (2026). Self-Administered Media Prescriptions: Training Algorithms to Deliver Inspirational Content to Reduce Stress and Increase Goal Motivation. Psychology of Popular Media. https://doi.org/10.1037/ppm0000669
Binz, M., Akata, E., Bethge, M., Brändle, F., Callaway, F., Coda-Forno, J., Dayan, P., Demircan, C., Eckstein, M. K., Éltető, N., Griffiths, T. L., Haridi, S., Jagadish, A. K., Ji-An, L., Kipnis, A., Kumar, S., Ludwig, T., Mathony, M., Mattar, M., … Schulz, E. (2025). A Foundation Model to Predict and Capture Human Cognition. Nature, 644(8078), 1002–1009. https://doi.org/10/g9r4fm
Cummins, J., Elson, M., & Hussey, I. (2025). Cognitive Dissonance in Large Language Models Is Neither Cognitive nor Dissonant. Proceedings of the National Academy of Sciences, 122(35), e2517912122. https://doi.org/10/g9zp53
Koch, T., Seeger, C., & Müller, P. (2025). Das Experiment in der Kommunikations- und Medienwissenschaft: Grundlagen, Durchführung und Auswertung experimenteller Forschung. Springer Fachmedien Wiesbaden. https://doi.org/10.1007/978-3-658-49131-4
Schröder, S., Morgenroth, T., Kuhl, U., Vaquet, V., & Paaßen, B. (2025, August 13). Large Language Models Do Not Simulate Human Psychology. https://doi.org/10.48550/arXiv.2508.06950
Francemone, C. J., Grizzard, M., Fitzgerald, K., Huang, J., & Ahn, C. (2022). Character Gender and Disposition Formation in Narratives: The Role of Competing Schema. Media Psychology, 25(4), 547–564. https://doi.org/10.1080/15213269.2021.2006718
Dienlin, T., Johannes, N., Bowman, N. D., Masur, P. K., Engesser, S., Kümpel, A. S., Lukito, J., Bier, L. M., Zhang, R., Johnson, B. K., Huskey, R., Schneider, F. M., Breuer, J., Parry, D. A., Vermeulen, I., Fisher, J. T., Banks, J., Weber, R., Ellis, D. A., … De Vreese, C. (2021). An Agenda for Open Science in Communication. Journal of Communication, 71(1), 1–26. https://doi.org/10.1093/joc/jqz052
Meier, A., & Reinecke, L. (2021). Computer-Mediated Communication, Social Media, and Mental Health: A Conceptual and Empirical Meta-Review. Communication Research, 48(8), 1182–1209. https://doi.org/10.1177/0093650220958224
Tamborini, R., Grady, S. M., Baldwin, J., McClaran, N., & Lewis, R. (2021). The Narrative Enjoyment and Appreciation Rationale. In P. Vorderer & C. Klimmt (Hrsg.), The Oxford Handbook of Entertainment Theory (S. 44–62). Oxford University Press. https://doi.org/10.1093/oxfordhb/9780190072216.013.3
Wolfers, L. N., & Schneider, F. M. (2021). Using Media for Coping: A Scoping Review. Communication Research, 48(8), 1210–1234. https://doi.org/10.1177/0093650220939778
Domahidi, E., & Haim, M. (2021, September 28). What Is Computational Communication Science and Why Would We Need a Podcast on That? [Audio recording]. Auf What is it about computational communication science (No. 1). Anchor. https://anchor.fm/ccs-pod/episodes/What-is-Computational-Communication-Science-and-why-would-we-need-a-podcast-on-that-e180odl
Prestin, A., & Nabi, R. (2020). Media Prescriptions: Exploring the Therapeutic Effects of Entertainment Media on Stress Relief, Illness Symptoms, and Goal Attainment. Journal of Communication, 70(2), 145–170. https://doi.org/10.1093/joc/jqaa001
Margolin, D. B. (2019). Computational Contributions: A Symbiotic Approach to Integrating Big, Observational Data Studies into the Communication Field. Communication Methods and Measures, 13(4), 229–247. https://doi.org/10/gg959f
Grizzard, M., Huang, J., Fitzgerald, K., Ahn, C., & Chu, H. (2018). Sensing Heroes and Villains: Character-Schema and the Disposition Formation Process. Communication Research, 45(4), 479–501. https://doi.org/10.1177/0093650217699934
van Atteveldt, W., & Peng, T.-Q. (2018). When Communication Meets Computation: Opportunities, Challenges, and Pitfalls in Computational Communication Science. Communication Methods and Measures, 12(2–3), 81–92. https://doi.org/10/gf8pnw
Reeves, B., Yeykelis, L., & Cummings, J. J. (2016). The Use of Media in Media Psychology. Media Psychology, 19(1), 49–71. https://doi.org/10.1080/15213269.2015.1030083
Knobloch-Westerwick, S. (2015). The Selective Exposure Self- and Affect-Management (SESAM) Model: Applications in the Realms of Race, Politics, and Health. Communication Research, 42(7), 959–985. https://doi.org/10.1177/0093650214539173
Open Science Collaboration. (2015). Estimating the Reproducibility of Psychological Science. Science, 349(6251), aac4716. https://doi.org/10.1126/science.aac4716
Rieger, D., Reinecke, L., Frischlich, L., & Bente, G. (2014). Media Entertainment and Well-Being: Linking Hedonic and Eudaimonic Entertainment Experience to Media-Induced Recovery and Vitality. Journal of Communication, 64(3), 456–478. https://doi.org/10.1111/jcom.12097
Oliver, M. B., & Bartsch, A. (2010). Appreciation as Audience Response: Exploring Entertainment Gratifications beyond Hedonism. Human Communication Research, 36(1), 53–81. https://doi.org/10/fkfhnn
Matthews, R. (2000). Storks Deliver Babies (P= 0.008). Teaching Statistics, 22(2), 36–38. https://doi.org/10.1111/1467-9639.00013
Cutrona, C. E. (1990). Stress and Social Support—in Search of Optimal Matching. Journal of Social and Clinical Psychology, 9(1), 3–14. https://doi.org/10.1521/jscp.1990.9.1.3
Zillmann, D. (1988). Mood Management through Communication Choices. American Behavioral Scientist, 31(3), 327–340. https://doi.org/10.1177/000276488031003005
Lazarus, R. S., & Folkman, S. (1984). Stress, Appraisal, and Coping. Springer Publishing Company.
![]()